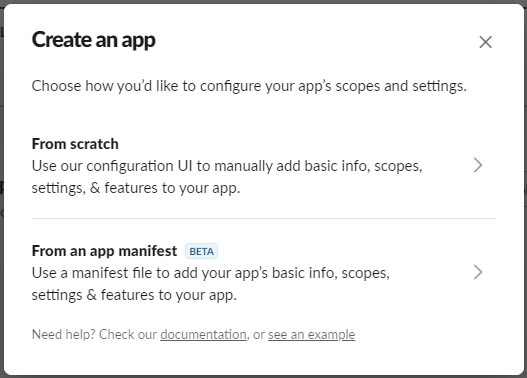
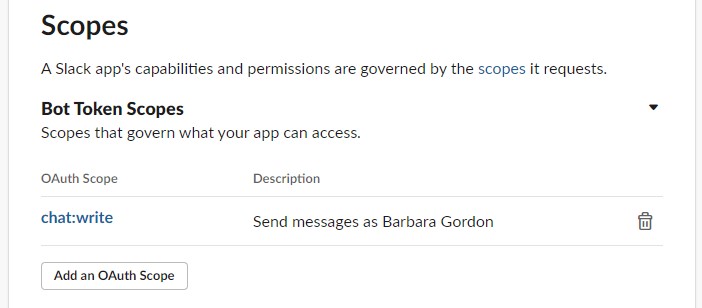
In Part 1 and 2 of this series I demonstrated how to create a Slack Integration and then use Azure Data Studio to Test the integration. These will need to be completed for the following SQL Server implementation to be completed
Preparing your SQL Server
So as stated in the beginning of this article series this uses SQL Server ML’s Python implementation and as this has been documented very well previously it would be better to read this if you have not set up this on your SQL Server.
Overview of SQL Server Machine Learning Services
Installation Information
Installing the SlackClient python package to an Instance
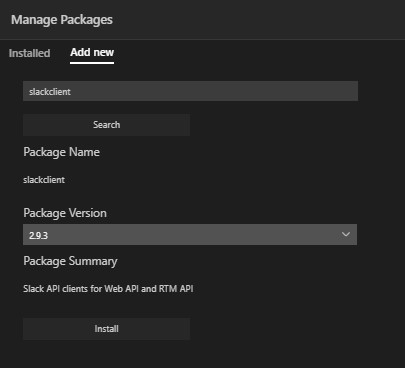
In the previous article we used the Azure DataStudio GUI to install slackclient. To Install this python package to the instance we are going to use the sqlmlutils package in ADS to load to a server instance using python.
import sqlmlutil
connection = sqlmlutils.ConnectionInfo(server="<sql server>", database="master")
sqlmlutils.SQLPackageManager(connection).install("SlackClient")
You will need to update the Server Name to your instance name, This code is using Windows Authentication. If you need to use SQL Authentication a username and Password needs to be added.
SQL Code Cutting
The Token code create in part one needs to be handled very securely. To this end I have put the token in to a Table. The final version uses an encrypted Column in the table and a signed stored procedure to access the the procedure to obscure this private information from users who wish to use the procedure
Use master
GO
CREATE TABLE SlackParams
(
Token_name NVARCHAR(80),
Information NVARCHAR(80)
)
INSERT INTO SlackParams (Token_Name, Information)
VALUES ('SLACK_BG_TOKEN','tokenstring from api.Slack.com ')
My Stored Procedure searches the table for a token. (multiple slack bots could be run off the same server). If a threadID is passed into the procedure if the update flag is 1 then the threadID is used to update the message. If the update = 0 then the threadId is used to post a new message under the original message.
python is a very format reliant language and the python scripts within the @pythonCode string have to be formatted in the same way. This means the SQL indentations can cause problems as there can be no preceding whitespace within the variables.
CREATE OR ALTER PROCEDURE slackToChannel
@Channel NVARCHAR(200) = '#dba' OUTPUT,
@ThreadId NVARCHAR(200) = '' OUTPUT,
@Message NVARCHAR(MAX),
@Update bit = FALSE
AS
BEGIN
DECLARE @PythonCode NVARCHAR(MAX)
DECLARE @CertId NVARCHAR(80)
DECLARE @ThreadInfo VARCHAR(500)
SELECT @CertId = Information
FROM master.dbo.SlackParams
WHERE Token_Name = 'SLACK_BG_TOKEN'
IF (@Update = 0)
BEGIN
--New Message
IF @threadId IS NULL OR @threadId = ''
BEGIN
SET @ThreadInfo = ''
END
ELSE
BEGIN
SET @threadInfo = ' , thread_ts = "' + @ThreadId + '"'
END
SET @PythonCode = N'import slack
# token is taken from the table Params and entered in thepython script below.
client = slack.WebClient(token=''' + @CertId + ''')
# post to channel submitted to the proc @channel
MessageReturn = client.chat_postMessage(channel="' + @Channel + '", text="' + @Message + '"' + @threadInfo + ')
thread_ts = MessageReturn["ts"]
channelid = MessageReturn["channel"]
'
EXECUTE sp_execute_external_script @language = N'Python',
@script = @PythonCode,
@params = N'@thread_ts VARCHAR(200) OUTPUT, @channelid VARCHAR(200) OUTPUT',
@channelid = @Channel OUTPUT, @thread_ts = @threadId OUTPUT
END
ELSE
BEGIN
--Update a Message
IF @threadId IS NULL OR @threadId = ''
BEGIN
PRINT 'Thread Id required to update a message!!'
END
ELSE
BEGIN
SET @threadInfo = ' , ts = "' + @threadId + '"'
SET @PythonCode = N'import slack
client = slack.WebClient(token=''' + @CertId + ''')
#update message posted to Channel
MessageReturn = client.chat_update(channel=''' + @Channel + ''', text="' + @Message + '"' + @threadInfo + ')
thread_ts = MessageReturn["ts"]
channelid = MessageReturn["channel"]'
EXECUTE sp_execute_external_script @language = N'Python',
@script = @PythonCode,
@params = N'@thread_ts VARCHAR(200) OUTPUT, @channelid VARCHAR(200) OUTPUT',
@channelid = @Channel OUTPUT, @thread_ts = @threadId OUTPUT
END
END
END
In the sp_execute_external_script call I am using
@params = N'@thread_ts VARCHAR(200) OUTPUT, @channelid VARCHAR(200) OUTPUT',
@channelid = @Channel OUTPUT, @thread_ts = @threadId OUTPUT
This means that the variables thread_ts and channelid within the python call can be outputted to the SQL side of the procedure. The output variables are mapped to the SQL variables @threadId and @channel
Due to the article formatting being iffy I have a notebook of the above information in Create Slack procedures for SQL Server
To test the Stored Procedure
The Stored Procedure can be tested, using the following code
EXEC slackToChannel @Channel = '#bot-integration', @Message = 'Hello World'
again errors that I have come up against when testing are around the firewall rules of my system. I had to go into Windows firewall outgoing rules and allow SQL Server to send. possible TCP/IP enabling had to be done as well.
Once the stored procedure is created it is possible to put the Stored procedure to use within Agent Jobs and called from within other procedures.
A complex example has been included has been written and is in this location Example usage. This example goes into more depth on Posting under an existing Message, and updating the messages. A Gif of the example is below.
This example Creates a Slack Post, Then under the post sets a simple progress bar, and below this updates an imaginary process. when each step is completed the progress bar and the Status is updated. Finally the original post is updated with a completed message and final status is updated.