One of the issues I see several times within SQL Server is people creating SQL Subqueries that reference the parent query so that an XML blob can be created.
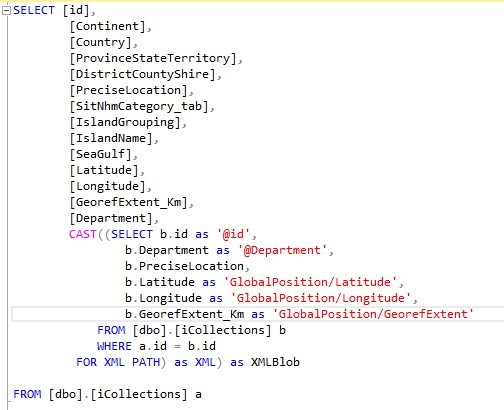
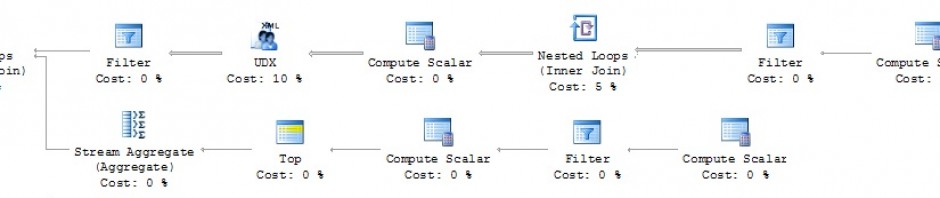
In this example The simple table query returns the table contents and creates an XML blob, to create this it references the ID in the subquery (b) and links to the ID in the main query (a). In the cases where there is only one ID record, for example primary key, the linking to the subquery is not required. This query is looking up each record causing which then creates a work table that then has 7216 scans, The iCollections table is scanned twice. in this example the table is only 182 pages. The issue is where the Table increases the size of the work table starts to increase proportionally.
Table 'Worktable'. Scan count 7216, logical reads 29578, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'iCollections'. Scan count 2, logical reads 364, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.It is possible to build a subquery that references the data in the main query. The above query can be rewritten without the linking to the parent query simply as.

As you can see the “FROM iCollections b” and the Where id = id join has also been removed. As the ID, in this case, is a unique field on the dataset it is possible to do this rewrite. If there were expectation of using other data rows from the table this would not be possible.
As there is only one table call the IO Statistics are now much simpler and the table is only scanned once. has reduced 29,760 logical page reads
Table 'iCollections'. Scan count 1, logical reads 182, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.The XML blob uses the primary Table to get the data for the blob. This can reduce the time taken for the server to return the result by half in this example. Less resources are consumed to get this information. so as the data scales the resource demand does not increase as rapidly.

Thanks to the Natural History Museum for providing data so I could produce these example patterns could be demonstrated. Natural History Museum provides access to some of it datasets via. https://data.nhm.ac.uk/
